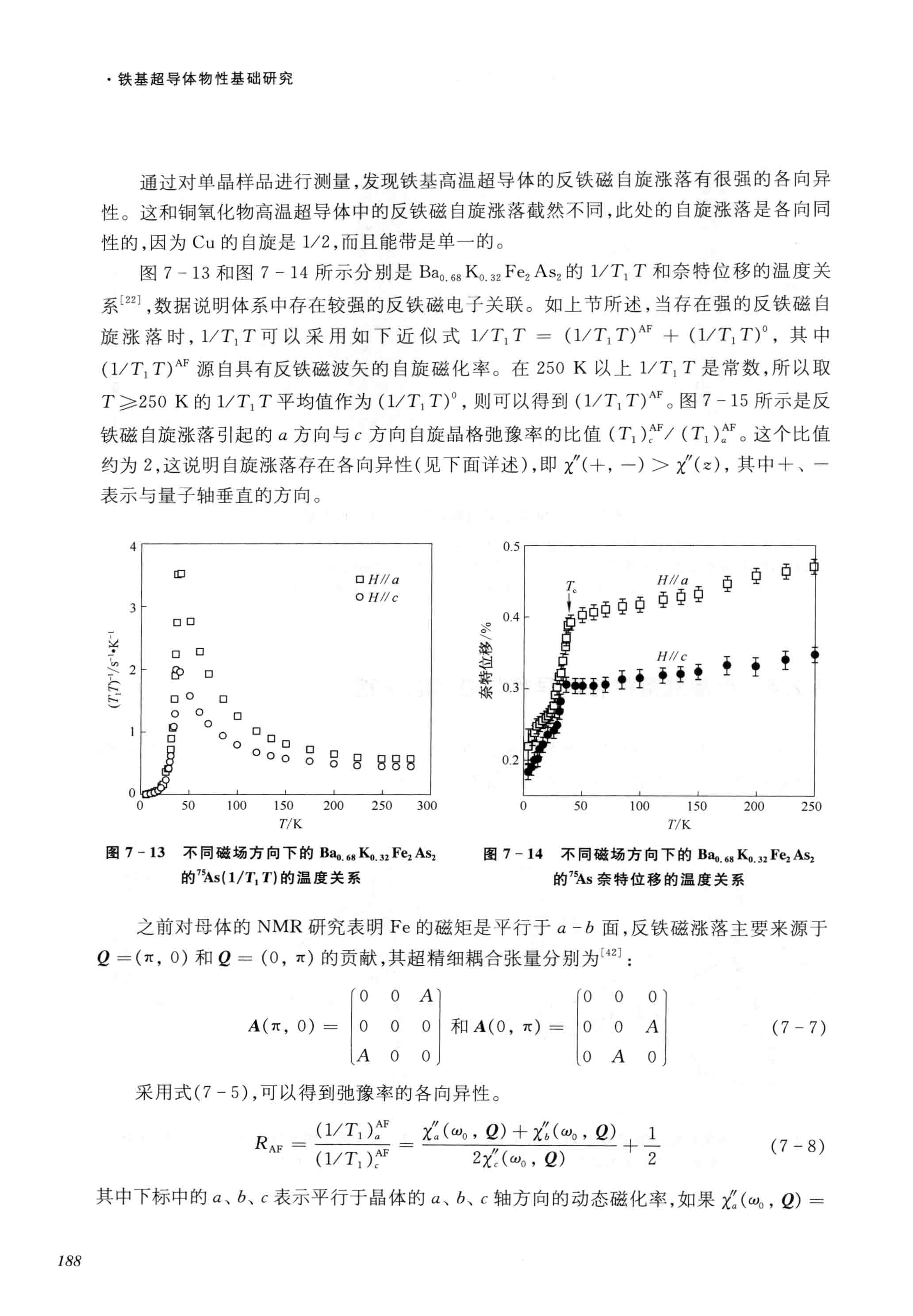
Exclusive access for LLM companies to largest Chinese non-fiction book collection in the world
annas-blog.org, 2023-11-04, Chinese version 中文版, Discuss on Hacker News
TL;DR: Anna’s Archive acquired a unique collection of 7.5 million / 350TB Chinese non-fiction books — larger than Library Genesis. We’re willing to give an LLM company exclusive access, in exchange for high-quality OCR and text extraction.
This is a short blog post. We’re looking for some company or institution to help us with OCR and text extraction for a massive collection we acquired, in exchange for exclusive early access. After the embargo period, we will of course release the entire collection.
High-quality academic text is extremely useful for training of LLMs. While our collection is Chinese, this should be even useful for training English LLMs: models seem encode concepts and knowledge regardless of the source language.
For this, text needs to be extracted from the scans. What does Anna’s Archive get out of it? Full-text search of the books for its users.
Because our goals align with that of LLM developers, we’re looking for a collaborator. We’re willing to give you exclusive early access to this collection in bulk for 1 year, if you can do proper OCR and text extraction. If you’re willing to share the entire code of your pipeline with us, we’d be willing to embargo the collection for longer.
Example pages
To prove to us that you have a good pipeline, here are some example pages to get started on, from a book on superconductors. Your pipeline should properly handle math, tables, charts, footnotes, and so on.



Send your processed pages to our email. If they look good, we will send you more in private, and we expect you to be able to quickly run your pipeline on those as well. Once we’re satisfied, we can make a deal.
Collection
Some more information about the collection. Duxiu is a massive database of scanned books, created by the SuperStar Digital Library Group. Most are academic books, scanned in order to make them available digitally to universities and libraries. For our English-speaking audience, Princeton and the University of Washington have good overviews. There is also an excellent article giving more background: “Digitizing Chinese Books: A Case Study of the SuperStar DuXiu Scholar Search Engine” (look it up in Anna’s Archive).
The books from Duxiu have long been pirated on the Chinese internet. Usually they are being sold for less than a dollar by resellers. They are typically distributed using the Chinese equivalent of Google Drive, which has often been hacked to allow for more storage space. Some technical details can be found here and here.
Though the books have been semi-publicly distributed, it is quite difficult to obtain them in bulk. We had this high on our TODO-list, and allocated multiple months of full-time work for it. However, recently an incredible, amazing, and talented volunteer reached out to us, telling us they had done all this work already — at great expense. They shared the full collection with us, without expecting anything in return, except the guarantee of long-term preservation. Truly remarkable. They agreed to ask for help in this way to get the collection OCR'ed.
The collection is 7,543,702 files. This is more than Library Genesis non-fiction (about 5.3 million). Total file size is about 359TB (326TiB) in its current form.
We’re open to other proposals and ideas. Just contact us. Check out Anna’s Archive for more information about our collections, preservation efforts, and how you can help. Thanks!